[原创]开源VOSK引擎免费语音转文字 0编程基础也可以操作
-
关键字:语音识别、语音转文字、录音转文字。
会议、课程录音需要转文字怎么办呢?最简单的办法当然都是上“讯飞听见”。上传、付费、下载结果。是的,需要付费。如果你有大量的音频内容需要进行文字识别(同时对精度要求不高)还有别的办法吗?你可以使用开源的语音识别引擎来处理这些录音。
下面我就来介绍一下如何使用VOSK API来处理你的录音。
VOSK是一个离线开源语音识别工具。它可以识别16种语言,包括中文。你可以把它看做知名语音识别引擎Kaldi ASR的一个Fork(分支)。
步骤1:安装Python3环境
前往 https://www.python.org/downloads/ 下载Windows环境版本(Python 3.8以上)。安装过程中选中“Add Python directory to 'PATH' environment variable”。选中之后,Python可以像系统自带命令一样,在所有CMD目录下运行。否则每次执行Python都需要输入它的目录位置。其他选项按默认即可。
(可选操作)步骤1a:替换下载镜像为清华大学镜像源
在命令行输入
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple这样对于国内用户来说下载速度会更快
步骤2:安装VOSK API库
打开CMD(命令提示符)输入
pip install vosk步骤3:配置目录并下载语音模型
在桌面创建 vosk 目录。
前往 https://alphacephei.com/vosk/models 下载中文语音模型。
或者直接点击下面的链接下载,并解压到vosk目录下。将解压出来的目录重命名为 “model”(不含引号)。
vosk-model-cn-0.1.zip
195M TBD Big narrowband Chinese model for server processing Apache 2.0步骤4:下载ffmpeg
前往 https://github.com/BtbN/FFmpeg-Builds/releases 下载ffmpeg,并将 ffmpeg.exe 解压到桌面 vosk 目录内
步骤5:安装并打开Notepad++ (或者使用你自己的高级文本编辑器)
前往 https://notepad-plus-plus.org/downloads/ 下载 notepad++
(国内镜像:http://www.pc6.com/softview/SoftView_13941.html)
安装打开,并创建新文件,拷贝以下内容:
# 使用方法 # 拷贝语音模型到当前目录下 并命名为 'model' # 拷贝ffmpeg.exe文件到当前目录下 # 执行 python test_ffmpeg.py speech.mp3 即可 #!/usr/bin/env python3 from vosk import Model, KaldiRecognizer, SetLogLevel import sys import os import wave import subprocess import json SetLogLevel(0) if not os.path.exists("model"): print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.") exit (1) sample_rate=16000 model = Model("model") rec = KaldiRecognizer(model, sample_rate) process = subprocess.Popen(['ffmpeg', '-loglevel', 'quiet', '-i', sys.argv[1], '-ar', str(sample_rate) , '-ac', '1', '-f', 's16le', '-'], stdout=subprocess.PIPE) f = open("result.txt", "w+") while True: data = process.stdout.read(10000) if len(data) == 0: break if rec.AcceptWaveform(data): re = rec.Result() print(re) re = json.loads(re) f.write(re['text'] + '\n') else: print(rec.PartialResult()) f.close() # print(rec.FinalResult())另存为 vosk 目录下的 voice2text.py 文件。
(可选步骤)步骤4a:调试命令行
步骤4给出的代码最适合处理mp3录音文件。如果你想要处理更多形式的音频,例如实时录音,或者更多的对话模式,例如电影对白,你可以参考官方的代码,地址是 https://github.com/alphacep/vosk-api/tree/master/python/example 。
步骤4的代码就是根据官方的 test_ffmpeg.py 代码修改而来。
步骤6:运行程序并识别文字
将需要识别的mp3/wav/mp4等音视频文件拷贝至 桌面的vosk目录内。例如,我需要识别的文件为 story.mp3。
进入CMD环境,输入 cd ~/Desktop/vosk 进入工作目录,然后输入
python voice2text.py story.mp3。系统开始识别语音内容,你可以看到识别的文字在窗口内一段段显示出来。
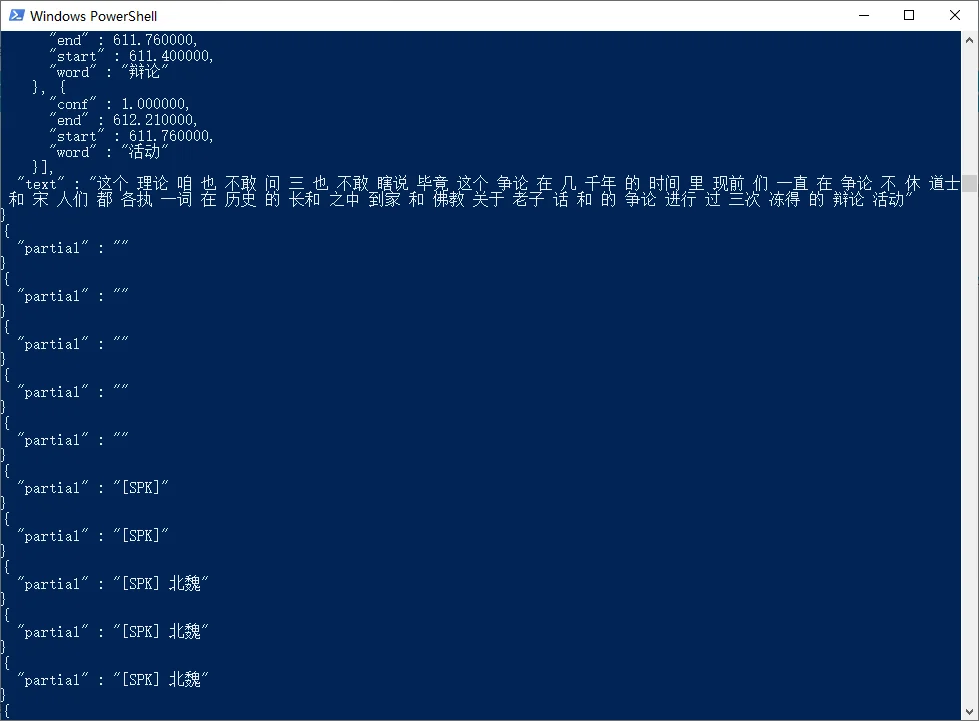
最终结果将存储到 vosk 目录下的 result.txt 文件内。你可以在word中进一步处理这些内容。